2020. 6. 4. 13:53ㆍAWS
ㅇ EMR?
> Elastic Map Reduce의 줄임말로, 빅데이터 프레임워크(ex. Hadoop, Spark) 실행을 간소화하는 관리형 클러스터 플랫폼
* Map Reduce: 흩어져있는 데이터를 Key, Value 형태로 연관 데이터끼리 묶는 Map단계와 Map화한 작업 중 중복 데이터를 제거하고 원하는 데이터를 추출하는 Reduce 단계로 처리 과정을 나누어 작업하는 것
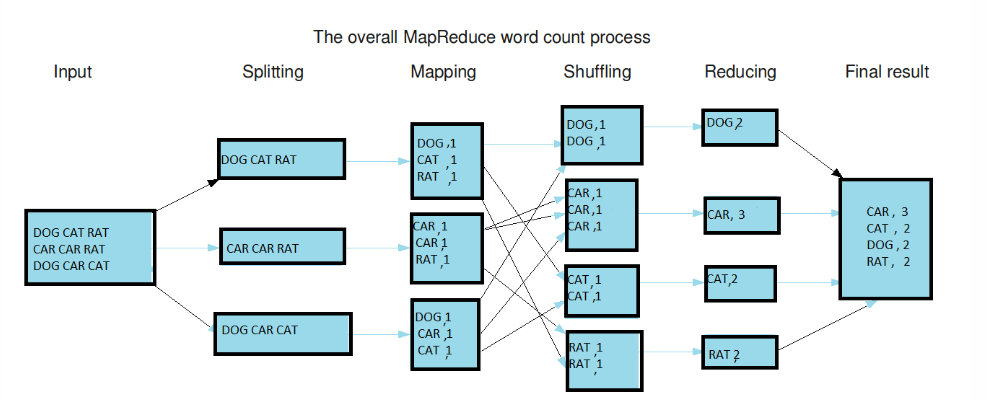
ㅇ EMR 구성요소
1) Master 노드
> 클러스터를 관리하며 분산 애플리케이션의 마스터 구성 요소 실행(ex. YARM Resource Manager Service, HDFS NameNode)
> 클러스터로 전송된 작업의 상태 추적 및 모니터링
2) Core 노드
> 실제 작업 및 저장 공간
> HDFS와 NodeManager 동작
3) Task 노드
> CPU, 메모리 리소스 추가하여 Hadoop, Spark 데이터에 대한 병렬 계산 작업 수행 기능 추가 가능
> HDFS가 없고, 오직 Task를 돌리기 위한 노드

* EMR은 VPC 외부에 있으며, VPC 내부에 있는 노드들은 DNS 조회를 통해 서로 통신함
ㅇ EMR 생성
> [EMR 서비스] - [클러스터 생성] 선택

> [고급 옵션으로 이동] 선택 후 소프트웨어 선택
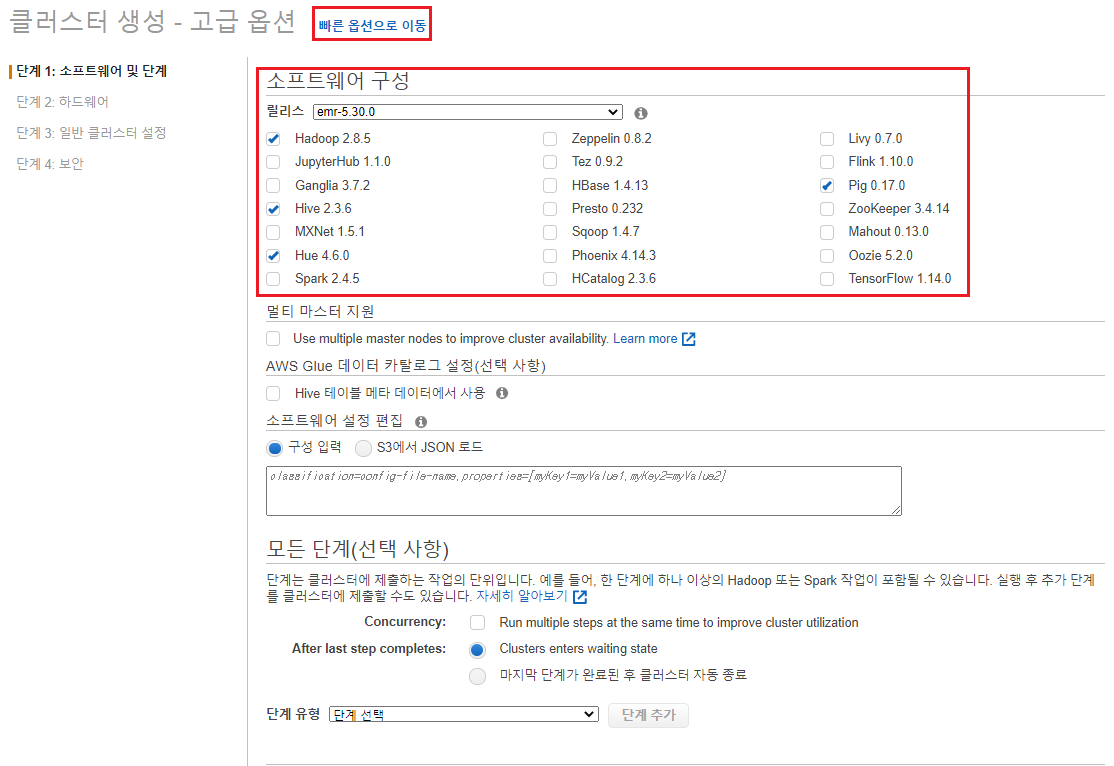
> EMR이 생성될 VPC 및 서브넷 선택

* 별다른 설정을 하지 않은 기본 VPC에 생성할 경우 "오류로 종료 상태 - 유효성 검사 오류" 에러 발생

> 노드의 인스턴스 유형 선택

> 클러스터 이름 및 로그가 저장될 버킷 지정

> 키페어 선택

ㅇ EMR 테스트
> EMR을 이용한 단어 갯수 파악 프로그램을 제작
> 퍼블릭 인스턴스에 Python3 설치
yum install -y python3

> 파이썬 설치 경로 확인
which python

> 파일 생성
* mapper.py: 특수문자, 공백 등을 제거해 정제된 단어를 포함한 줄만 출력하는 프로그램
* reducer.py: 출현한 단어와 그 빈도를 출력하는 프로그램
* book.txt: 단어, 출현연도, 총 출현 횟수, 출현한 책 갯수가 순차 기입된 텍스트 파일

> 쉘 테스트
cat book.txt | ./mapper.py | sort -k1,1 | ./reducer.py | sort -k2,2n

* ERROR: bad interpreter: Permission Denied 발생 시
> 파이썬 코드 최상단에 위치한 매직넘버로 기입된 경로 설정이 잘못된 것
> 클러스터 생성 후, CLI 접속
* ERROR: Could not connect to the endpoint URL 발생 시
> aws configure 실행 시, Default Region을 공백이 아닌, EMR이 있는 위치로 설정

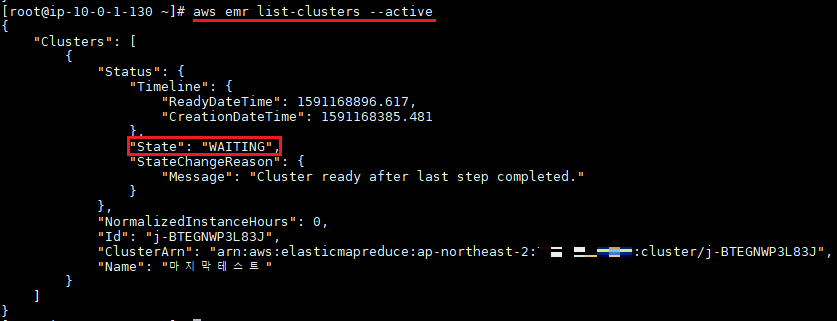
> 명령어를 통해 클러스터 상태 확인
* 처음에는 STARTING상태로, WAITING 상태가 되어야 클러스터가 사용 가능
aws emr list-clusters --active
> 스텝 추가
* 출력 S3 위치에 해당하는 디렉토리는 S3에 동일한 이름의 폴더가 없어야함

> describe-step 명령어를 통해 해당 스텝의 상태 확인
aws emr describe-step --cluster-id (클러스터 ID) --step-id (스텝 ID)

> 결과값이 저장되었는지 확인하기 위해 S3 버킷 검사

> EMR 사용 시, part-00000 ~ part-00006으로 분할된 파일로 S3에 output으로 지정한 폴더에 저장됨

ㅇ 결과 비교
> sort 명령어를 통해 두 번째 인자인 숫자 기준으로 정렬

> diff 명령어를 통해 두 텍스트 파일 비교

> 해당 데이터는 약 4백만 줄로 쉘 스크립트 돌리는 것만으로도 짧은 시간 내에 작업 가능하지만, 훨씬 더 큰 데이터를 Input으로 사용할 경우 EMR이 더 빠를 것
'AWS' 카테고리의 다른 글
| [AWS IAM] 32. 정책 세부내용 확인 (0) | 2020.06.16 |
|---|---|
| [AWS] 31. 2Tier-Architecture (0) | 2020.06.08 |
| [AWS ElastiCache] 29. ElastiCache (0) | 2020.05.26 |
| [AWS EFS] 28. EFS (0) | 2020.05.25 |
| [AWS VPC] 26. Peering Connection (0) | 2020.05.13 |