[AWS] CLI를 통해 S3 사용하기
안녕하세요, 달콤한달팽이입니다.🐌😎
이전 글에서 S3를 생성하고, 사용하는 방법을 실습해보며 CLI를 사용하는 방식에 대해 가볍게 알아보았습니다.
이번 글에선 CLI를 사용하는 방법을 조금 더 자세하게 알아보는 시간을 가져볼 예정입니다.
S3를 처음 사용해보시는 분이라면 아래 글을 먼저 읽어보시는 것을 권장드려요!
[AWS] S3 사용하기
안녕하세요, 달콤한달팽이입니다.🐌😎 오늘은 AWS를 사용하여 객체를 저장하고, 이를 사용하는 방법을 알아보겠습니다. S3란? S3란, AWS에서 제공하는 객체 스토리지 서비스로 파일을 저장하기
sweetysnail1011.tistory.com
AWS CLI란?
AWS CLI란, AWS의 오픈 소스 도구로 명령어를 통해 AWS 서비스와 상호 작용을 할 수 있는 기능을 의미합니다.
AWS에서는 CLI를 통해 거의 모든 기능을 수행할 수 있기 때문에,
명령어를 숙지하고 사용 방법이 어렵다는 단점을 제외한다면 아주 강력한 도구가 될 수 있습니다!
1) 사전 작업 - 권한 부여
사실상 모든 AWS 리소스를 제어할 수 있는 CLI 사용을 위해선,
CLI를 사용하는 사용자가 올바른 사용자인지 검증할 방법이 필요합니다.
이를 위해선 크게 두 가지 방법이 존재합니다.
(1) 엑세스 키 사용
- 장점: Access Key, Secret Access Key만 보유하고 있다면 어떤 서버에서든 사용 가능
- 단점: Access Key를 분실 및 탈취로 인한 보안적인 문제가 발생할 수 있음
(2) 서버 내 권한 부여
- 장점: Key 분실로 인한 보안 위험이 적음
- 단점: 권한이 부여된 특정 서버에서만 CLI 사용 가능
이렇듯 두 가지 검증 방식의 장단점이 명확하기 때문에 상황에 맞게 잘 고려하시는 것이 중요합니다!
2) 사전 작업 - CLI 설치 확인 및 설치
AWS CLI를 사용하기 위해선 CLI가 설치되어 있어야 합니다.
이를 확인하기 위해선 CLI를 사용할 서버에 접속하여 Access Key를 등록하는 명령어를 사용해봅시다!
aws configure
성공 시 아래와 같이 Access Key를 물어보는 문구가 출력됩니다.

실패 시 아래와 같이 aws 명령어를 찾을 수 없다는 문구가 출력됩니다.

AWS CLI가 설치되어 있지 않으신 분들은 아래 작업을 잘 따라와주세요!
AWS에서 제공하는 zip파일을 다운로드, 압축해제 후 이를 실행해 주세요.
$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
$ unzip awscliv2.zip
$ sudo ./aws/install
이후 다시 명령어를 사용해 보면 정상적으로 사용이 가능할 것입니다.
참 쉽죠?!
이제 엑세스 키를 발급받았다면 Key를 등록해 주세요
(저는 서버에 권한을 부여하는 방식을 사용할 것이므로 그냥 넘어가도록 하겠습니다.)

3 ) 커맨드 옵션
CLI를 사용할 때에 사용 가능한 옵션은 수없이 많겠지만,
이 중에서도 몇 가지 옵션은 특히 자주 사용되므로 알아두면 좋습니다!
강제 수행(--force)
버킷이 비어있지 않아도 강제로 삭제되도록 설정하는 옵션입니다.
주로 버킷 삭제(rb) 명령어에 사용됩니다.
커맨드 테스트(--dryrun)
명령어가 수행됐을 때, 어떤 결과가 예상될지 테스트를 진행해보는 옵션입니다.
하위 디렉터리 포함(--recursive)
명령어를 수행할 때, 하위 디렉터리를 포함할 때 사용되는 옵션입니다.
주로 파일 복제(cp), 파일 삭제(rm) 명령어에 사용됩니다.
ex) aws s3 cp . s3://{버킷명} --recursive
파일 포함 & 제외(--include & --exclude)
지정된 객체만 포함 혹은 제외되도록 설정하는 옵션입니다.
주로 파일 복제(cp), 파일 삭제(rm) 명령어에 사용됩니다.
ex) aws s3 cp . s3://{버킷명} --exclude "*.txt"
ex) aws s3 cp . s3://{버킷명} --include "*.txt"
앞으로 사용될 명령어의 모 버킷 경로는 모두 s3://{버킷명}/{버킷 경로}로 구성되어있다는점 참고바랍니다!
4 - 1) S3 목록 확인(ls)
우선 현재 생성되어 있는 S3의 목록을 확인해보겠습니다.
아래의 명령어를 통해 현재 4개의 버킷이 있다는 것을 알 수 있습니다.
$ aws s3 ls {Bucket_DIR}
4 - 2) S3 생성 및 삭제(mb & rb)
현재 생성되어는 버킷이 아닌 다른 버킷을 사용하고 싶을 경우, 새로운 버킷 생성이 필요할 수 있습니다.
$ aws s3 mb s3://{NEW_BUCKET}
또는 필요하지 않은 버킷을 삭제해야할 때도 있습니다.
(버킷 안에 내용물이 남아있는데 강제로 삭제를 원할 경우 --force 명령어를 추가해주세요!)
$ aws s3 rb s3://{OLD_BUCKET}
4 - 3) 파일 이동(mv)
파일을 S3 버킷의 지정된 경로로 이동을 시켜야할 경우 아래와 같이 명령어를 사용합니다.
저는 동일한 버킷의 cli 경로에 있는 hello,cli.txt 파일을 console 경로로 이동시켜 보겠습니다.
(--dryrun 명령어를 통해 실제 명령어 수행(파일 이동)은 이루어지지 않고, 예상 결과만 출력하는 것도 가능합니다!)
$ aws s3 mv {이동 대상 경로} {파일 저장 경로}
4 - 4) 파일 복사(cp)
만약 로컬과 버킷 간 파일 복사가 필요할 경우 아래와 같이 파일 복사를 수행합니다.
(--recursive 명령어를 통해 디렉터리와 이에 포함된 파일들도 복사할 수 있습니다!)
$ aws s3 cp {이동 대상 경로} {파일 저장 경로}
3 - 5) 파일 동기화(sync)
만약 로컬과 버킷 간 중복되는 파일은 유지하고, 없는 파일은 복사하는 동기화를 수행하고 싶을 경우 동기화 명령어를 사용합니다.
$ aws s3 sync {동기 주체} {동기 대상}
하지만 동기화를 수행해도 기존에 없는 파일을 복사해오기만 할 뿐, 삭제는 진행하지 않는다는 특징이 있습니다.
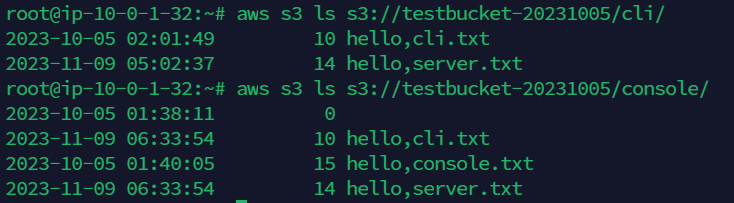
지금까지 CLI를 통해 S3를 제어하는 방법에 대하여 알아보았습니다.
보다 더 많은 내용을 확인하고 싶을 경우, AWS 공식 문서를 확인해보시길 바랍니다!!
감사합니다.